- Joined
- Nov 7, 2014
- Messages
- 571
The
Suppose that we wanted to use a hashtable as a 2d array with dimensions 1 and 100_000, should we make (X = 1, Y = 100_000), (X = 100_000, Y = 1) or it doesn't matter?
I tried to do an fps benchmark using this (Perl) script (which should be easy to translate to another language):
It generates some vJass script that does the fps benchmark.
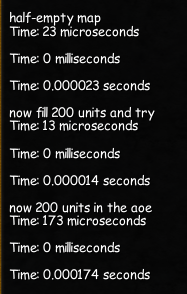
According to my tests it seems that using the hashtable as a [X][Y] (X < Y), is better than [Y][X] (X < Y), i.e
the lower dimension should be passed as the
hashtable native provides an API that resembles the access of a 2d array:
JASS:
native SaveInteger takes hashtable table, integer parentKey, integer childKey, integer value returns nothing
native LoadInteger takes hashtable table, integer parentKey, integer childKey returns integer
...
local integer i1 = LoadInteger(ht, X, Y)
// resembles:
local integer i2 = ht[X][Y]Suppose that we wanted to use a hashtable as a 2d array with dimensions 1 and 100_000, should we make (X = 1, Y = 100_000), (X = 100_000, Y = 1) or it doesn't matter?
I tried to do an fps benchmark using this (Perl) script (which should be easy to translate to another language):
Code:
use strict;
use warnings;
use feature 'say';
my $OUTPUT_FILE_NAME = 'hashtable-dim-benchmark.j';
my $MAX_ITEMS = 100_000;
my $LOAD_INTEGER_CALLS_COUNT = 20_000;
my $TIMEOUT = '1.0 / 20.0';
# 1 --> SaveInteger(ht, X, 0, X); LoadInteger(ht, X, 0)
# 0 --> SaveInteger(ht, 0, X, X); LoadInteger(ht, 0, X)
# where X is in the range [0, $MAX_ITEMS)
#
my $USE_LEFT_DIM = 1;
my @indices; # an array of indicies that we use to generate the LoadInteger calls
{
my @all_indices;
for (my $i = 0; $i < $MAX_ITEMS; $i += 1) {
push @all_indices, $i;
}
@all_indices = shuffle(\@all_indices);
for (my $i = 0; $i < $LOAD_INTEGER_CALLS_COUNT; $i += 1) {
push @indices, $all_indices[$i];
}
}
my $s = '';
{
$s .= qq|library HashtableDimBenchmark initializer init\n|;
$s .= qq|\n|;
}
# globals
{
$s .= qq|globals\n|;
$s .= qq| private constant integer MAX_ITEMS = $MAX_ITEMS\n|;
if ($USE_LEFT_DIM) {
$s .= qq| private hashtable ht = InitHashtable() // [MAX_ITEMS][1]\n|;
}
else {
$s .= qq| private hashtable ht = InitHashtable() // [1][MAX_ITEMS]\n|;
}
$s .= qq| private integer items_count = 0\n|;
$s .= qq| private integer index = 0\n|;
$s .= qq|endglobals\n|;
}
# function ht_init
{
$s .= qq|\n|;
$s .= qq|private function ht_init takes nothing returns nothing\n|;
$s .= qq| loop\n|;
if ($USE_LEFT_DIM) {
$s .= qq| call SaveInteger(ht, index, 0, index)\n|;
}
else {
$s .= qq| call SaveInteger(ht, 0, index, index)\n|;
}
$s .= qq| set index = index + 1\n|;
$s .= qq| if index >= MAX_ITEMS then\n|;
$s .= qq| call BJDebugMsg("ht[0][0] = " + I2S(LoadInteger(ht, 0, 0)))\n|;
if ($USE_LEFT_DIM) {
$s .= qq| call BJDebugMsg("ht[$MAX_ITEMS - 1][0] = " + I2S(LoadInteger(ht, $MAX_ITEMS - 1, 0)))\n|;
}
else {
$s .= qq| call BJDebugMsg("ht[0][$MAX_ITEMS - 1] = " + I2S(LoadInteger(ht, 0, $MAX_ITEMS - 1)))\n|;
}
$s .= qq| return\n|;
$s .= qq| endif\n|;
$s .= qq|\n|;
$s .= qq| // trying not to hit the op-limit\n|;
$s .= qq| set items_count = items_count + 1\n|;
$s .= qq| if items_count > 1000 then\n|;
$s .= qq| set items_count = 0\n|;
$s .= qq| call ExecuteFunc(SCOPE_PRIVATE + "ht_init")\n|;
$s .= qq| return\n|;
$s .= qq| endif\n|;
$s .= qq| endloop\n|;
$s .= qq|endfunction\n|;
}
# function benchmark_loop
{
$s .= qq|\n|;
$s .= qq|private function benchmark_loop takes nothing returns nothing\n|;
$s .= qq| local integer i\n|;
for my $index (@indices) {
if ($USE_LEFT_DIM) {
$s .= qq|set i = LoadInteger(ht, $index, 0)\n|;
}
else {
$s .= qq|set i = LoadInteger(ht, 0, $index)\n|;
}
}
$s .= qq|endfunction\n|;
}
# init, when the Esc key gets pressed start the fps benchmark
{
$s .= qq|\n|;
$s .= qq|private function start_fps_benchmark takes nothing returns nothing\n|;
$s .= qq| call ClearTextMessages()\n|;
$s .= qq|\n|;
if ($USE_LEFT_DIM) {
$s .= qq| call BJDebugMsg("running fps benchmark for hashtable of [$MAX_ITEMS][1] (LoadInteger calls: $LOAD_INTEGER_CALLS_COUNT, timeout: $TIMEOUT)")\n|;
}
else {
$s .= qq| call BJDebugMsg("running fps benchmark for hashtable of [1][$MAX_ITEMS] (LoadInteger calls: $LOAD_INTEGER_CALLS_COUNT, timeout: $TIMEOUT)")\n|;
}
$s .= qq| call TimerStart(CreateTimer(), $TIMEOUT, true, function benchmark_loop)\n|;
$s .= qq|endfunction\n|;
$s .= qq|\n|;
$s .= qq|private function init takes nothing returns nothing\n|;
$s .= qq| local trigger t\n|;
$s .= qq|\n|;
$s .= qq| call ht_init()\n|;
$s .= qq|\n|;
$s .= qq| set t = CreateTrigger()\n|;
$s .= qq| call TriggerRegisterPlayerEventEndCinematic(t, Player(0))\n|;
$s .= qq| call TriggerAddAction(t, function start_fps_benchmark)\n|;
$s .= qq|\n|;
$s .= qq| call BJDebugMsg("enter the /fps command to show the fps and then")\n|;
$s .= qq| call BJDebugMsg("press Esc to start the benchmark")\n|;
$s .= qq|endfunction\n|;
}
{
$s .= qq|endlibrary\n|;
}
MAIN: {
# print $s;
if (!write_string_to_file($s, $OUTPUT_FILE_NAME)) {
exit(1);
}
exit(0);
}
sub shuffle { my ($array) = @_;
my @result = @$array; # copy the array
for (my $i = 0; $i < @result; $i += 1) {
my $r = get_random_integer(0, $i);
my $tmp = $result[$i];
$result[$i] = $result[$r];
$result[$r] = $tmp;
}
@result
}
# Returns a random integer in the range [$x, $y] (both bounds are inclusive).
sub get_random_integer { my ($x, $y) = @_;
return $x + int(rand() * ($y - $x + 1));
}
sub write_string_to_file { my ($string, $file_name) = @_;
my $err = !open(my $file, '>', $file_name);
if ($err) {
say qq|could not open file "$file_name" for writing"|;
return ''; # false
}
if (! print {$file} $string) {
say qq|could not write string to file "$file_name"|;
return '';
}
if (!close($file)) {
say qq|could not close file "$file_name"|;
return '';
}
1; # true
}It generates some vJass script that does the fps benchmark.
According to my tests it seems that using the hashtable as a [X][Y] (X < Y), is better than [Y][X] (X < Y), i.e
the lower dimension should be passed as the
parentKey argument, and the higher dimension should be passed as the childKey parameter to the Save|Load* hashtable natives.