- Joined
- Aug 18, 2009
- Messages
- 4,100

As map projects grow large, macroscopic effects occur. A lot of different stuff needs to work in unison. You need to maintain order to keep the overview, build systems to not grovel at low levels forever. When anything does not work as intended, an investigation commences. You insert debug messages to track down the point of failure. Some parameter values may be invalid in general, so you catch them in separate branches and throw an exception.
In this tutorial I want to present some concepts to tackle different problems in map scripts in wc3. Part of those concepts require compiler/language support to be realized.
As indicated within the introduction, a lot of code can throw a lot of (different) errors and this raises the question where to unload those piles of text. If you use game messages and care to see something more than four short lines, you spam your screen, disturbing the game and blocking normal game messages. Also you may skip lines because too many strike at once. That is why it is good practice to number the messages, but let's focus more on bug identification later.

(screenshot sponsored by Crigges, thanks)
A 2nd option would be to make a switchable multiboard. You may arrange it in pages and therefore keep better track and view old entries. Still you only see a few lines at once and they cannot be too long.
A 3rd option is to dump it in quests (quest descriptions), which is very disturbing for the gameplay and inconvenient. By modifying the FrameDefs, you can stuff a lot of lines in there but it's badly controlable and you constantly need to refactor the whole description -> gigantic string concatenations and you reach string size limits.
So the ingame methods in wc3 are all no good. It would be much better to display game information in a separate window. Well, you can. The disadvantage is that it is slow to execute but it trumps by being resistant to one issue I have not mentioned yet: fatal errors, game termination. Those mean the loss of all ingame information. Since you cannot predict them, you cannot properly save all the data either.
Since you may want to keep different logs, a game session should be communicated. This can simply be done by having a known index file, which stores an integer counter but you have to read it (localfiles needs to be active). Use the Preloader native to execute the jass code of the index file. For example the SetPlayerName native works. Now you have read the last session id, increase it and rebuild the index file. All loggings can now be done on session-dependent paths.
Of course your log reader tool must be told what session to read from. So it should access the index file as well. It runs in a separate process and may likely be faster than wc3, therefore still see the old session. To avoid this, you can make the tool wait for a signal output from the game, respectively in case the game may be faster, periodically output changing signals, so the reader detects it at some point.
Finally the tool knows where to look at, periodically checks the file for new lines, can parse out the preload stuff and display the results accurately.
For efficiency, you should not write to a single file endlessly because recreating the file (wc3 rewrites the whole file instead of appending) gets ineffective after ~500 lines. Clear the preload buffer and pick a new one in intervals.
Labeling every debug message "I am a bug" hardly helps. It needs to identify itself to tell the developer what happened and where. So the scope is the bare minimum. Include an increasing index number and a timestamp, too, then a brief description and maybe parameters.
Except for those parameters, debug messages can be solved in compiletime. One could index and encrypt debug messages, thereby shorten the file output. I do not know if the performance gain is worthwhile, for sure it is not feasible to have it map specific and you do not really need to protect the logs.
A typical problem is the early termination of threads. This can happen because you divide by zero, or use an uninitialized variable or due to the operation limit. The first two can be solved well/partly by the compiler: Replace the division by an own function that checks the divisor, look if there is an assignment to the local variable before the lines that use it.
Global variables however are not covered this way because outside of the function things are not a simple sequence. You can still give those variables a default value so it at least does not break the thread. This may not necessarily be good to do though because you actually want to catch the malpractice.
The operation limit nails the coffin. It is hardly accessible by compilers because branches and loops are dynamic.
I want to talk about two strategies to catch thread breaks:
Forced return
There are several ways to create a new thread in wc3. As trigger actions, trigger conditions, via TriggerExecute/TriggerEvaluate or event, as timer callbacks, conditional enums, action enums or ExecuteFunc.
ExecuteFunc should be avoided in normal application and trigger conditions outshine trigger actions.
Trigger actions that are realized as trigger conditions, meaning where you do not use the return value of TriggerEvaluate, are targets of this method because this apparently superfluous feature can be used to determine if the function ended correctly. If a function does not return, TriggerEvaluate states false. So you just have to replace all return instructions by return true (and add another return true before endfunction).
The advantage of this method is that it is lightweight. Even so, it requires a caller, it must be started via TriggerEvaluate.
Firing the trigger via event directly is not covered, instead redirect the event to another trigger, which then evaluates your actual code.
Other thread types that do not make use of a return value are timer callbacks and enum actions (and ExecuteFunc). If you want, you can replace them by TriggerEvaluates, too, though that might be less performant.
A good idea is to mark functions by their use, so the compiler knows how to threat them in order to match the transformations/methods.
Overageing
The idea of the 2nd approach is to list all currently running threads. Inject code into the entry function to catch the start and the end.
If the thread is still listed after it terminated in reality, it must have been broken. Since recursion of the same function is plausible, there has to be some kind of allocation.
The only question is when to print the list because threads can be nested. When is no Thread object supposed to exist any longer? Either you have to have a caller at the top level again or you do it separately with a periodic timer for example.
The advantage here is that it can be used with any type of thread.
A neat option interpreters for common programming languages offer is, whenever a debug point occurs, to display a coherent call route how this code part was reached.
Doing this in jass would probably be hella slow and spammy, so I limit it to threads.
That's similar to Overageing of thread break detection. Before invoking a thread, you increase a counter and use it as an index in an array to store the thread's id under the current value. Afterwards you decrease the counter again. This realizes a stack and as soon as a bug strikes, you iterate over the whole array to assemble the current nesting.
If the top thread is a timer callback, you may check GetExpiredTimer() for information and prepend it.
You can identify a thread well by the scope and the local function name. It can be attached to the trigger or timer. My suggestion is to make the compiler assign every function its name and attach the function to the specific container. Albeit native container structures do not support the code type, you can infact index codes and there is a possibility to retrieve them dynamically.
As long as you do not destroy the boolexprs of single functions, GetHandleId(Condition(code)) returns the same function-dependent integer. This integer can be passed around as a substitute. If you really need to cast it back to code, you can shadow all functions by another function that only has to task to set a global code variable to the original function.
A further precarious topic is posed by leaks. You create an object but forget/fail to release it. In a dynamic context, that is quite difficult to track down because you would literally have to consider all references, build chains from them and decide what the roots are.
Rather than drafting a garbage collector, a view of the currently allocated instances/the amount is nice, too. This is simply done by injecting into the allocate/deallocate methods and you can register all the classes on init, so the counters/allocation lists are connected to the class names and dynamically addressed in another list.
Another improvement: Object instances should be recognizable, therefore they may pass an additional parameter to the create function as their name. Picking the current stack trace would be very specific, maybe overkill. You can determine a name from potential other parameters to the constructor or the static script position (scope, line number, line content).
Object editor objects are indicated by a raw id of four letters. They are commonly processed as integers in jass and are then displayed in decimal (base ten) system when printed, which is why you do not recognize the object on the spot. Remedy is given by an Ascii library.
Checking the type of an agent (PurgeandFire)
If you ever get in the situation that you have to identify the exact type of an agent (unit, timer, effect, etc), the new return bug can help:
This way you can trial & error through the different types until someone signals "yeah, that's me". Every type should have an id, for example a unique integer or a string.
Not all agent types can be covered this way because the hashtable is limited to a selection. You could actually expand it to handles in general but the hashtable possesses even few thereof.
In this tutorial I want to present some concepts to tackle different problems in map scripts in wc3. Part of those concepts require compiler/language support to be realized.
Logfiles and live coverage
As indicated within the introduction, a lot of code can throw a lot of (different) errors and this raises the question where to unload those piles of text. If you use game messages and care to see something more than four short lines, you spam your screen, disturbing the game and blocking normal game messages. Also you may skip lines because too many strike at once. That is why it is good practice to number the messages, but let's focus more on bug identification later.
(screenshot sponsored by Crigges, thanks)
A 2nd option would be to make a switchable multiboard. You may arrange it in pages and therefore keep better track and view old entries. Still you only see a few lines at once and they cannot be too long.
A 3rd option is to dump it in quests (quest descriptions), which is very disturbing for the gameplay and inconvenient. By modifying the FrameDefs, you can stuff a lot of lines in there but it's badly controlable and you constantly need to refactor the whole description -> gigantic string concatenations and you reach string size limits.
So the ingame methods in wc3 are all no good. It would be much better to display game information in a separate window. Well, you can. The disadvantage is that it is slow to execute but it trumps by being resistant to one issue I have not mentioned yet: fatal errors, game termination. Those mean the loss of all ingame information. Since you cannot predict them, you cannot properly save all the data either.
How to transfer data to another program?
First read Debug I/O by Almia. It uses the Preload natives in order to store text files with own contents on the hard disk, though it's still wrapped into the frames of preload files. You cannot start other programs this way, which is why you have to activate the log reader yourself. It is a good idea however to make a launcher that both starts the tool and wc3 with the map in singleplayer. Also you should run wc3 in windowed mode. It's better to do stuff in parallel and you can see the log reader without having to have a 2nd monitor.Since you may want to keep different logs, a game session should be communicated. This can simply be done by having a known index file, which stores an integer counter but you have to read it (localfiles needs to be active). Use the Preloader native to execute the jass code of the index file. For example the SetPlayerName native works. Now you have read the last session id, increase it and rebuild the index file. All loggings can now be done on session-dependent paths.
JASS:
function initLog
pName = GetPlayerName(GetLocalPlayer())
SetPlayerName(GetLocalPlayer(), I2S(SESSION_ID))
Preloader("index.ini") //modifies the local player's name
SESSION_ID = S2I(GetPlayerName(GetLocalPlayer())) + 1
PreloadGenClear()
PreloadGenStart()
Preload("\")\n" + "call SetPlayerName(GetLocalPlayer(), \"" + I2S(SESSION_ID) + "\")" + "\ncall Preload(\"")
SetPlayerName(GetLocalPlayer(), pName)
PreloadGenEnd("index.ini")
endfunctionOf course your log reader tool must be told what session to read from. So it should access the index file as well. It runs in a separate process and may likely be faster than wc3, therefore still see the old session. To avoid this, you can make the tool wait for a signal output from the game, respectively in case the game may be faster, periodically output changing signals, so the reader detects it at some point.
JASS:
function periodicFunction
PreloadGenClear()
Preload(I2S(GetRandomInt(INT_MIN, INT_MAX)))
PreloadGenEnd("index.ini")
endfunctionFinally the tool knows where to look at, periodically checks the file for new lines, can parse out the preload stuff and display the results accurately.
For efficiency, you should not write to a single file endlessly because recreating the file (wc3 rewrites the whole file instead of appending) gets ineffective after ~500 lines. Clear the preload buffer and pick a new one in intervals.
General bug identification
Labeling every debug message "I am a bug" hardly helps. It needs to identify itself to tell the developer what happened and where. So the scope is the bare minimum. Include an increasing index number and a timestamp, too, then a brief description and maybe parameters.
#511 (30.145): [BUG] Math.SquareRoot: randicand is negative {params: radicant=-9}
Except for those parameters, debug messages can be solved in compiletime. One could index and encrypt debug messages, thereby shorten the file output. I do not know if the performance gain is worthwhile, for sure it is not feasible to have it map specific and you do not really need to protect the logs.
Detecting thread breaks
A typical problem is the early termination of threads. This can happen because you divide by zero, or use an uninitialized variable or due to the operation limit. The first two can be solved well/partly by the compiler: Replace the division by an own function that checks the divisor, look if there is an assignment to the local variable before the lines that use it.
Global variables however are not covered this way because outside of the function things are not a simple sequence. You can still give those variables a default value so it at least does not break the thread. This may not necessarily be good to do though because you actually want to catch the malpractice.
The operation limit nails the coffin. It is hardly accessible by compilers because branches and loops are dynamic.
I want to talk about two strategies to catch thread breaks:
Forced return
There are several ways to create a new thread in wc3. As trigger actions, trigger conditions, via TriggerExecute/TriggerEvaluate or event, as timer callbacks, conditional enums, action enums or ExecuteFunc.
ExecuteFunc should be avoided in normal application and trigger conditions outshine trigger actions.
Trigger actions that are realized as trigger conditions, meaning where you do not use the return value of TriggerEvaluate, are targets of this method because this apparently superfluous feature can be used to determine if the function ended correctly. If a function does not return, TriggerEvaluate states false. So you just have to replace all return instructions by return true (and add another return true before endfunction).
JASS:
function someThreadEntryFunction returns boolean
...
if abortCase
...
return true //injected
//return //commented out/replaced
endif
...
return true //injected
endfunctionThe advantage of this method is that it is lightweight. Even so, it requires a caller, it must be started via TriggerEvaluate.
Firing the trigger via event directly is not covered, instead redirect the event to another trigger, which then evaluates your actual code.
JASS:
function redirect
c = GetTriggeringTrigger().c
if not TriggerEvaluate(c)
DebugPrint("thread "+c.id)
endif
endfunction
function TriggerAddCode takes trigger t, code c
t.c = CodeWrapperTrigger.create(c)
TriggerAddCondition(t, redirect)
endfunction
TriggerAddCode(t)
TriggerRegisterEvent(t)Other thread types that do not make use of a return value are timer callbacks and enum actions (and ExecuteFunc). If you want, you can replace them by TriggerEvaluates, too, though that might be less performant.
A good idea is to mark functions by their use, so the compiler knows how to threat them in order to match the transformations/methods.
JASS:
timerFunction periodicUpdate
DebugPrint("yada")
endfunctionOverageing
The idea of the 2nd approach is to list all currently running threads. Inject code into the entry function to catch the start and the end.
JASS:
struct Thread
List runningList
method destroy
runningList.remove(this)
static method create takes id returns thistype
this = allocate()
this.id = id
runningList.add(this)
return this
endmethod
endstruct
function someThreadEntryFunction
Thread t = Thread.create(id)
...do stuff
t.destroy()
endfunctionIf the thread is still listed after it terminated in reality, it must have been broken. Since recursion of the same function is plausible, there has to be some kind of allocation.
The only question is when to print the list because threads can be nested. When is no Thread object supposed to exist any longer? Either you have to have a caller at the top level again or you do it separately with a periodic timer for example.
JASS:
function periodicFunction
for t in Thread.runningList
DebugPrint(t.id)
t.destroy()
endfor
endfunctionThe advantage here is that it can be used with any type of thread.
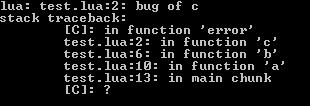
Thread stack trace
A neat option interpreters for common programming languages offer is, whenever a debug point occurs, to display a coherent call route how this code part was reached.
Doing this in jass would probably be hella slow and spammy, so I limit it to threads.
That's similar to Overageing of thread break detection. Before invoking a thread, you increase a counter and use it as an index in an array to store the thread's id under the current value. Afterwards you decrease the counter again. This realizes a stack and as soon as a bug strikes, you iterate over the whole array to assemble the current nesting.
JASS:
function RunTrigger takes trigger t
call IncStack(t)
call TriggerEvaluate(t.id)
call DecStack()
endfunction
function PrintStack
DebugPrint("stack traceback:")
for i=stack.maxIndex downto stack.minIndex
DebugPrint("->" + stack.getElement(i).id)
endfor
DebugPrint("---/")
endfunctionIf the top thread is a timer callback, you may check GetExpiredTimer() for information and prepend it.
JASS:
function GetExpiredTimerSafe returns timer
if (GetTriggerEventId() != null)
return null
endif
return GetExpiredTimer()
endfunction
function PrintStack
...
if (GetExpiredTimerSafe() != null)
DebugPrint("->" + GetExpiredTimerSafe().id)
endif
endfunctionThread identification, code indentification
You can identify a thread well by the scope and the local function name. It can be attached to the trigger or timer. My suggestion is to make the compiler assign every function its name and attach the function to the specific container. Albeit native container structures do not support the code type, you can infact index codes and there is a possibility to retrieve them dynamically.
JASS:
function GetCodeId takes code c returns integer
return GetHandleId(Condition(c))
endfunction
function GetCodeName takes code c returns string
return LoadStr(FUNCS_TABLE, GetCodeId(c), NAME_KEY)
endfunction
init
SaveStr(FUNCS_TABLE, GetCodeId(function someFunc), NAME_KEY, "someFunc")
endinitAs long as you do not destroy the boolexprs of single functions, GetHandleId(Condition(code)) returns the same function-dependent integer. This integer can be passed around as a substitute. If you really need to cast it back to code, you can shadow all functions by another function that only has to task to set a global code variable to the original function.
JASS:
function IdToCode takes integer id returns code
TriggerEvaluate(LoadTriggerHandle(FUNCS_TABLE, id, SHADOW_FUNC_KEY)
return GLOBAL_CODE_VAR
endfunction
function someFunc
...
endfunction
function someFunc_shadow
GLOBAL_CODE_VAR = function someFunc
endfunction
init
trigger t = CreateTrigger()
TriggerAddCondition(t, function someFunc_shadow)
SaveTriggerHandle(FUNCS_TABLE, GetCodeId(function someFunc), SHADOW_FUNC_KEY, t)
endinitAllocation tracking, object identification
A further precarious topic is posed by leaks. You create an object but forget/fail to release it. In a dynamic context, that is quite difficult to track down because you would literally have to consider all references, build chains from them and decide what the roots are.
Rather than drafting a garbage collector, a view of the currently allocated instances/the amount is nice, too. This is simply done by injecting into the allocate/deallocate methods and you can register all the classes on init, so the counters/allocation lists are connected to the class names and dynamically addressed in another list.
JASS:
class SomeClass
integer classIndex
method destroy
...
deregisterClassInstance(classIndex, this)
endmethod
static method allocate
...
registerClassInstance(classIndex, this)
endmethod
init
structIndex = registerClass("abc")
endinitAnother improvement: Object instances should be recognizable, therefore they may pass an additional parameter to the create function as their name. Picking the current stack trace would be very specific, maybe overkill. You can determine a name from potential other parameters to the constructor or the static script position (scope, line number, line content).
JASS:
class AnotherClass
method createCorrespondingSomeClass
SomeClass obj = SomeClass.create("AnotherClass.createCorrespondingSomeClass")Misc
Object editor objects are indicated by a raw id of four letters. They are commonly processed as integers in jass and are then displayed in decimal (base ten) system when printed, which is why you do not recognize the object on the spot. Remedy is given by an Ascii library.
Checking the type of an agent (PurgeandFire)
If you ever get in the situation that you have to identify the exact type of an agent (unit, timer, effect, etc), the new return bug can help:
JASS:
function Agent2<Type> takes agent a returns <Type>
call SaveFogStateHandle(hashtable, 0, 0, ConvertFogState(GetHandleId(a)))
return Load<Type>Handle(hashtable, 0, 0)
endfunction
function IsAgent<Type> takes agent a returns boolean
return (Agent2<Type>(a) != null)
endfunctionThis way you can trial & error through the different types until someone signals "yeah, that's me". Every type should have an id, for example a unique integer or a string.
JASS:
function GetAgentType takes agent a returns integer
if IsAgentUnit(a) then
return TYPE_ID_UNIT
endif
if IsAgentTimer(a) then
return TYPE_ID_TIMER
endif
if IsAgentEffect(a) then
return TYPE_ID_EFFECT
endif
...
if (a == null) then
return TYPE_ID_NULL
endif
return TYPE_ID_INVALID
endfunctionNot all agent types can be covered this way because the hashtable is limited to a selection. You could actually expand it to handles in general but the hashtable possesses even few thereof.
This concudes the tutorial. Maybe you have some more tricks up your sleeve or improvements. I will also add stuff if more comes to mind or what I forgot to talk about.
Attachments

Last edited:






